ITEEDU
awk 中的 print 命令把输入文件中选择的数据输出。
当 awk 读取文件的一行,根据指定的 输入域分隔符 把行分开, FS,awk 的一个环境变量(见 第 6.3.2 节 “输出分隔符”)。它被预先定义为一个或者多个空格或者制表符。
变量 $1, $2, $3, ..., $N 把输入行的第一第二第三直到最后一个域保存起来。变量 $0 把整行的值保存起来。在下面的图片描述中,我们看到 df 命令输出有6栏。
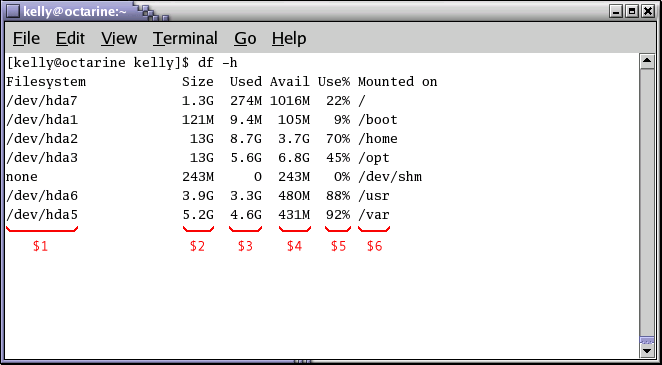
在 ls -l 的输出,有9栏。 print 语句像这样使用这些域:
kelly@octarine ~/test>ls-l| awk'{ print $5 $9 }'160orig 121script.sed 120temp_file 126test 120twolines 441txt2html.shkelly@octarine ~/test>
这个命令把包含文件大小的第五栏和包含文件名的最后一栏打印出来。除非你使用正式的方法来用一个逗号来分割你想打印的列,否则输出并不十分适合阅读。这样的情况下,默认的输出分割字符,通常是一个空格,将被放入每个输出域。
没有格式化,只使用输出分隔符的话看上去比较破,插入几个制表符和指示输出的标记会使它变得漂亮很多:
kelly@octarine ~/test>ls-ldh*| grep-vtotal| \ awk'{ print "Size is " $5 " bytes for " $9 }'Size is 160 bytes for orig Size is 121 bytes for script.sed Size is 120 bytes for temp_file Size is 126 bytes for test Size is 120 bytes for twolines Size is 441 bytes for txt2html.shkelly@octarine ~/test>
注意反斜杠的用法,让shell不把它翻译成分隔命令而使其在下一行继续很长的输入。虽然命令行的输入实际上是没有长度限制的,但是你的显示器不是,打印的纸当然也不是。使用反斜杠也允许拷贝和粘贴以上行到一个终端窗口。
ls 的 -h 选项用来支持把大文件的字节数转换成更容易读的格式。当把目录作为参数的时候长列表的输出显示目录中快的总数。这行对我们并没有什么用处,所以我们加上一个*。同样的原因我们同样加上 -d 选项,万一*对一个目录展开。
在这个例子中的反斜杠提示了一行的延长。见 第 3.3.2 节 “转义字符”。
甚至在反序中你也能取出任何栏的的数字。下面的例子证明了最危险的区分。
kelly@octarine ~>df-h| sort-rnk5| head-3| \ awk'{ print "Partition " $6 "\t: " $5 " full!" }'Partition /var : 86% full! Partition /usr : 85% full! Partition /home : 70% full!kelly@octarine ~>
下表给出了特殊格式化字符的总揽:
引用,$和其他元字符应该使用反斜杠来进行转义。
用斜杠把正则表达式包含起来可以当作一个pattern。然后正则表达式测试整个文本的每条记录。语法如下:
awk 'EXPRESSION { PROGRAM }'
file(s)
下面的例子现实了只有本地磁盘设备的信息,网络文件系统没有显示:
kelly is in ~>df-h| awk'/dev\/hd/ { print $6 "\t: " $5 }'/ : 46% /boot : 10% /opt : 84% /usr : 97% /var : 73% /.vol1 : 8%kelly is in ~>
斜杠也需要转义,因为对于 awk 它们有着特殊的含义。
下面的另外一个例子是我们在 /etc 目录搜索以 “.conf” 结尾和 “a” 或者 “x” 开头的文件,使用扩展的正则表达式:
kelly is in /etc>ls-l| awk'/\<(a|x).*\.conf$/ { print $9 }'amd.conf antivir.conf xcdroast.conf xinetd.confkelly is in /etc>
这个例子说明了在正则表达式中.的特殊意义。第一个表明了我们想要搜索在第一个搜索字符串之后的任何字符,第二个因为是要查找字符串的一部分所以被转义了(文件名的结束)。
为了在输出之前加上注释,使用BEGIN语句:
kelly is in /etc>ls-l| \ awk'BEGIN { print "Files found:\n" } /\<[a|x].*\.conf$/ { print $9 }'Files found: amd.conf antivir.conf xcdroast.conf xinetd.confkelly is in /etc>
加上 END 语句能插入文本在整个输入被处理之后:
kelly is in /etc>ls-l| \ awk'/\<[a|x].*\.conf$/ { print $9 } END { print \ "Can I do anything else for you, mistress?" }'amd.conf antivir.conf xcdroast.conf xinetd.conf Can I do anything else for you, mistress?kelly is in /etc>
由于往往命令都有点长,你可能想把他们放到脚本中,来重用它。一个 awk 脚本包含定义pattern和动作的awk语句。
作为一个说明,我们将建立一个报告来显示占用率最高的分区,参见 第 6.2.2 节 “格式化域”。
kelly is in ~>catdiskrep.awkBEGIN { print "*** WARNING WARNING WARNING ***" } /\<[8|9][0-9]%/ { print "Partition " $6 "\t: " $5 " full!" } END { print "*** Give money for new disks URGENTLY! ***" } kelly is in ~> df -h | awk -f diskrep.awk *** WARNING WARNING WARNING *** Partition /usr : 97% full! *** Give money for new disks URGENTLY! ***kelly is in ~>
awk 先打印一个开始信息,然后格式化所有包含一个8或者9开头的词的行,然后后接一个数字和百分符号,然后加入结束信息。
![[注意]](images/note.png) |
语法高亮 |
|---|---|
|
Awk是一个编程语言。他的语法能被大多数能对其他语言比如c,bash,HTML进行语法高亮编辑器所识别。 |