ITEEDU
Tesseract-ocr体系结构
站长原创,版权所有ITEEDU,2011-07-15
功能
Tesseract作为OCR的一个识别工具,其可以很容易地检测出图像中的文本信息。
Tesseract 是一款开源的光学字符串识别(OCR)项目,能够识别图像验证码。比如存在一个格式为TIF的文字图片,Tesseract能够识别出该图片中的文字,将识别到的文字写入到一个文本文件中,识别效果很不错。如果想要识别不同语言的文字图像,需要下载响应的支持包,才能让Tesseract识别更多格式的图像。
特点
开源的;轻量级的;有自动学习能力(可以通过训练来建立自己的常用字符串);支持版面分析。
应用场景
tesseract是一个非常强大的图片识别工具,有较大的几率将图片中的字符抓取出来。
其目前主要应用场景也就是图片中的文字信息的提取:
比如图片:

通过处理后,可以将其信息显示在txt文件中:
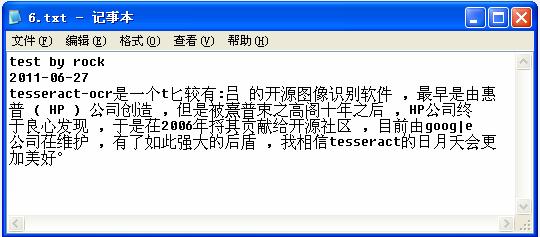
目前,它应用较多的地方还是对网站验证码信息的提取。
Tesseract-ocr体系结构简析
了解了tesseract-ocr的功能、特点和应用场景,我们应该很容易理解:
tesseract本身代码是由c/c++混编而成的,其中有用的简单的接口函数几乎都是在baseapi.h中。
从其处理过程中,不难得出:它还需要有一个image处理的类,及相关的方法;这样子,读取图片后,生成image对象,再获取相关的参数;当然还需要有对image对象的读取,版面分析等接口函数;再次,它还定义了很多自身的数据类型,比如:BITS16、array_record、BLOCK、IMAGE等;而且它具有自学的能力。
现在,我们从头有调理地简单讲述一下子:
(1)tesseract::TessBaseAPI,基础的接口函数,包含了初始化,简单的处理图片文字信息,版面分析的结果体等。
(2)IMAGE,只是一个类,里边封装了相关的图片操作,包括图片的读取,图片参数信息的获取等。
(3)其他,包括数据类型声明,相关结构体声明,跨平台处理,命令端参数提取等。
事实上,我们在实际中用到的就是前两个里边的东西。